TokenAttention#
Transformers form the foundation of modern large language models. During autoregressive decoding, these models cache key-value tensors of context tokens in GPU memory for fast generation of the next token. However, these caches occupy a large amount of GPU memory. Due to the variability in request lengths, the unpredictability of cache sizes exacerbates this problem, leading to severe memory fragmentation in the absence of appropriate memory management mechanisms.
To alleviate this issue, PagedAttention was proposed to store KV cache in non-contiguous memory spaces. It divides the KV cache of each sequence into multiple blocks, with each block containing keys and values for a fixed number of tokens. This method effectively controls memory waste within the last block during attention computation. While PagedAttention alleviates memory fragmentation to some extent, it still leaves room for memory waste. Additionally, when handling multiple high-concurrency requests, the efficiency of memory block allocation and deallocation is low, resulting in poor memory utilization.
To address the above challenges, we introduced TokenAttention, an attention mechanism that manages key and value cache at the token level. Compared to PagedAttention, our TokenAttention can not only minimize memory fragmentation and achieve efficient memory sharing, but also promote efficient memory allocation and deallocation. It allows for more precise and fine-grained memory management, thereby optimizing memory utilization.
Features |
PagedAttention |
TokenAttention |
|---|---|---|
Low Memory Fragmentation |
✓ |
✓ |
Efficient Memory Sharing |
✓ |
✓ |
Efficient Memory Allocation and Deallocation |
✗ |
✓ |
Fine-grained Memory Management |
✗ |
✓ |
The operation mechanism of TokenAttention is shown in the figure below:
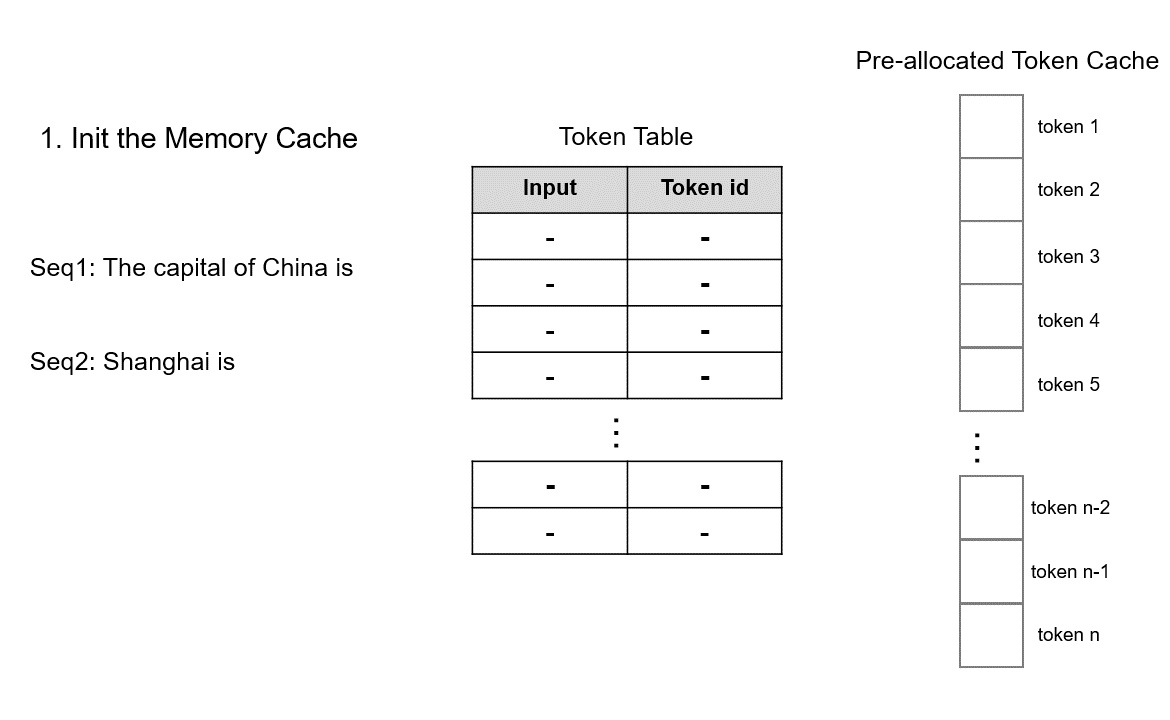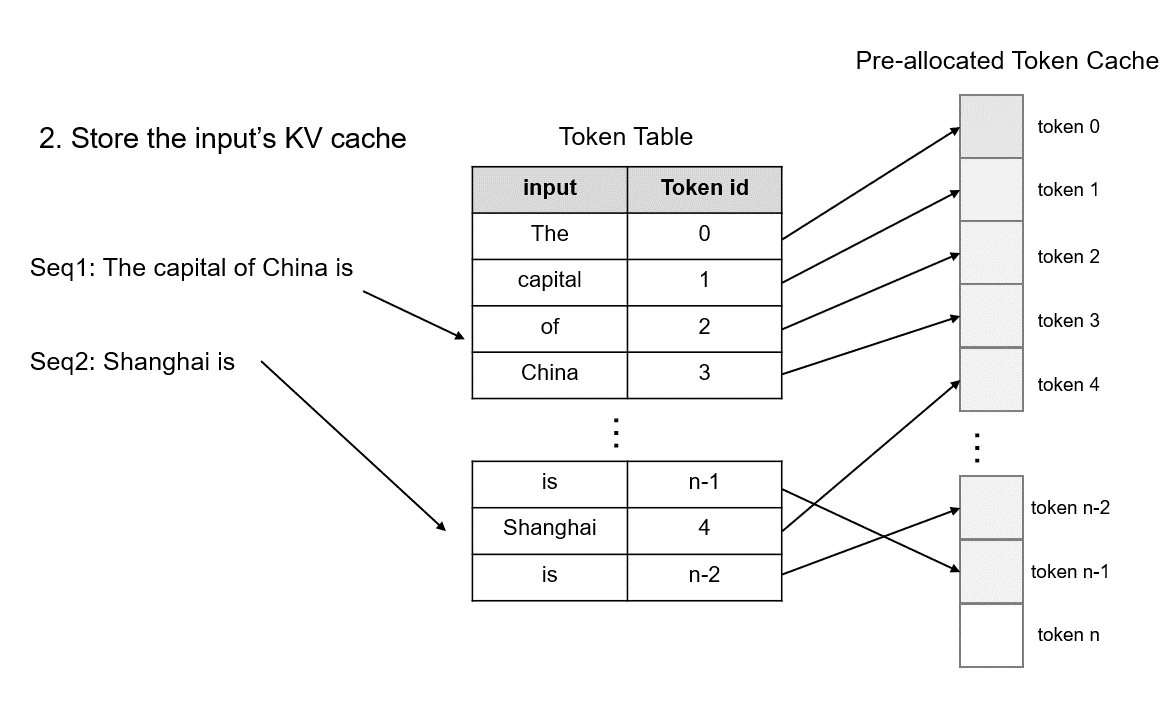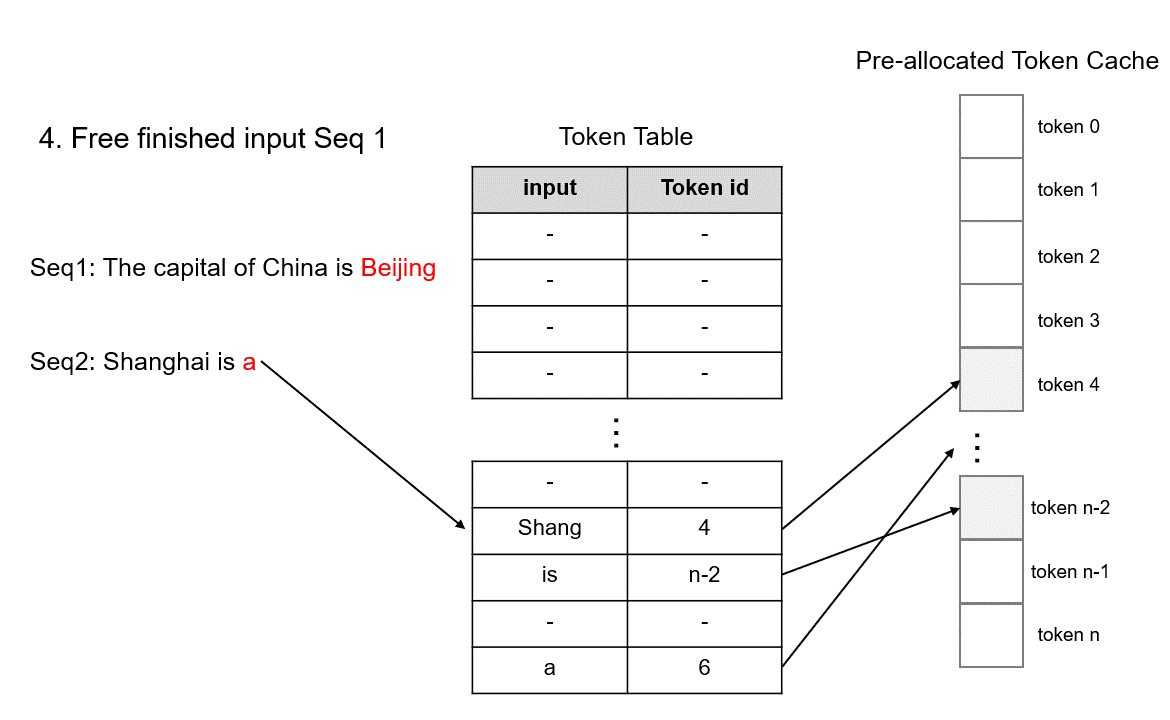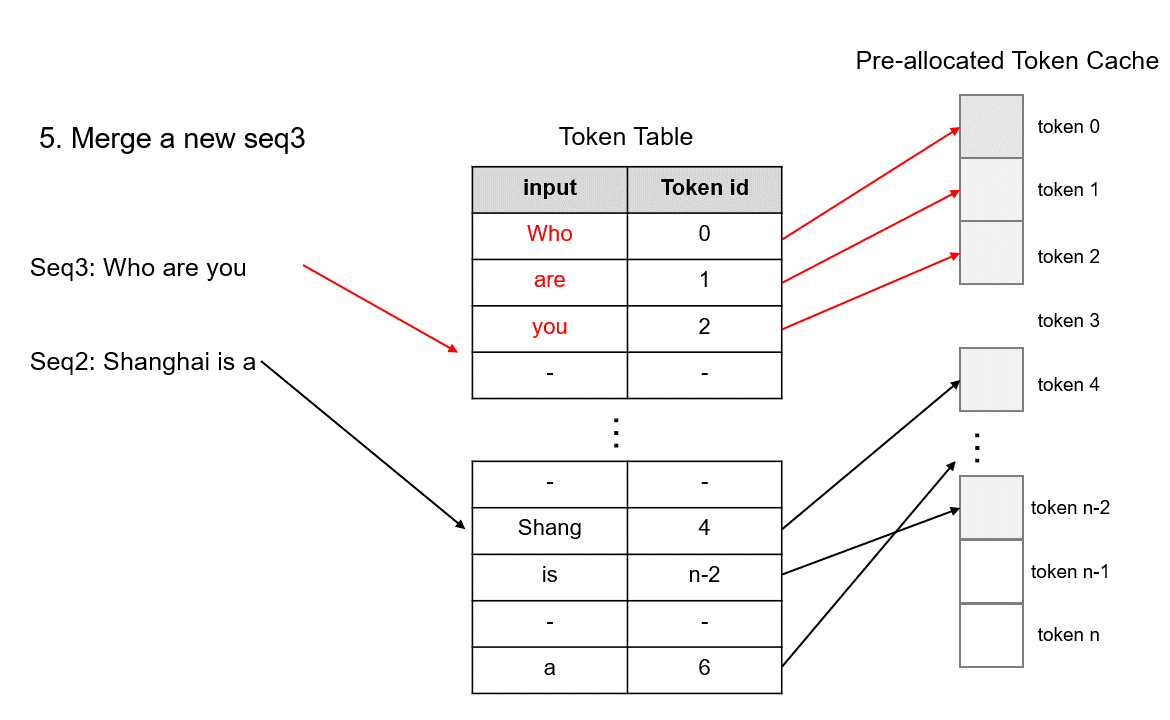
During model initialization, KV cache is pre-allocated according to the user-set max_total_token_num, and a Token Table is created to record the actual storage location of input tokens.
When processing new requests, the system first checks if there is available contiguous space in the pre-allocated token cache for storing key-value (KV) cache. TokenAttention tends to allocate contiguous graphics memory space for requests to minimize memory access during inference. Only when contiguous space is insufficient will non-contiguous memory be allocated for requests. Since memory management is performed token by token, TokenAttention achieves almost zero waste and produces higher throughput compared to vllm.
We implemented an efficient TokenAttention operator using OpenAI Triton. When provided with query vectors, this operator can efficiently retrieve the corresponding KV cache based on the Token Table and perform attention computation.
After request completion, the corresponding memory can be quickly released by deleting records on the token table, making way for scheduling new requests. Since TokenAttention pre-allocates all KV cache space during model initialization, it can efficiently release memory for completed requests and merge requests from different batches during dynamic scheduling, effectively maximizing GPU utilization.
Specific steps are as follows:
During model initialization, the system pre-allocates KV cache memory according to the user-set
max_total_token_numand creates a Token Table to record the actual storage location of input tokens.When processing new requests, the system first checks if there is available contiguous space in the pre-allocated token cache for storing KV Cache. TokenAttention tends to allocate contiguous memory for requests to minimize memory access during inference. Only when contiguous space is insufficient will non-contiguous memory be allocated for requests. The allocated space is recorded in the Token Table for subsequent attention computation.
For caching newly generated tokens, it’s only necessary to find unused space from the pre-allocated token cache and add the corresponding entries to the token table. Additionally, to efficiently allocate and deallocate cache, we utilize Torch Tensor’s parallel computing capabilities on GPU to manage the state of pre-allocated token cache. First, we define the state as follows:
self.mem_state = torch.ones((size,), dtype=torch.bool, device="cuda") self._mem_cum_sum = torch.empty((size,), dtype=torch.int32, device="cuda") self.indexes = torch.arange(0, size, dtype=torch.long, device="cuda") self.can_use_mem_size = size
mem_staterecords the usage state of the cache, where 1 represents unused and 0 represents used._mem_cum_sumis used for the cumulative sum ofmem_state, used to efficiently identify and select unused space for cache allocation. The allocation process is as follows:torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self._mem_cum_sum) # select_index = torch.logical_and(self._mem_cum_sum <= need_size, self.mem_state == 1) select_index = self.indexes[select_index] self.mem_state[select_index] = 0 self.can_use_mem_size -= len(select_index)
It can be observed that our cache state management is entirely completed on GPU, fully utilizing torch’s parallel capabilities, thereby allowing the system to efficiently allocate cache space for each request.
After request completion, the corresponding memory can be quickly released by deleting records on the
Token Table, making way for scheduling new requests.self.can_use_mem_size += free_index.shape[0] self.mem_state[free_index] = 1
Due to token-level GPU memory management, TokenAttention can achieve zero waste of GPU memory. It can accurately calculate how many new tokens the system can accommodate for computation. Therefore, when combined with
Efficient Routerto manage requests, it can continuously add new requests during inference, fully utilizing every piece of GPU memory and maximizing GPU utilization.